
如何利用好身边的数据,成为企业价值是否能够延续的重要指标。
多数据源的集中日益成为趋势,当不同类型,来源的数据海量增长时,企业不仅需要收集更多的数据,更需要整合数据孤岛、将数据集中处理和分析做为决策流程的一部分。对于一些企业来说,要求数据的整合和分析并最终用于决策的时间非常短。随着内存数据库技术的发展,使得高速分析巨大而复杂的数据群(通常在GB到TB级)成为可能。
离线分析通常由海量数据 (TB到PB级) 的存储和分析需求驱动,数据源通常是半结构化和机构化数据,包含 Web 访问日志,CDN日志,应用系统日志及设备使用日志等。基于hadoop可构建各种对历史规律进行多维统计预测,准实时分析以及对客户进行聚类、分类等数据挖掘应用。
环亚时代针对企业级用户有丰富的实时在线处理和高速在线分析、离线数据分析、多维统计的经验,可以完美的提供基于企业级大数据的咨询、实施、服务等。
通过为企业量身定制的核心解决方案,可为企业达成如下目标:
对快速变化的业务环境做出迅速响应,帮助企业提高运营效率 企业的业务能够从数据收集中预见到发展前景,快速的将所获得信息及时分类并做出明智的决策。 数据分析之后所看到的再也不是过去发生的事,而是此刻正在发生的事。能让企业准确把握市场动向,采取及时准确的行动。 释放数据潜能,使企业快速改进服务,降低成本,节约时间。环亚时代-CFB(CloudRise For Bigdata)企业大数据平台解决方案,实际上是帮助企业快速构建自己的大数据处理中心,同时为企业大数据平台提多方位的运维监控服务,在提高企业大数据运算能力的同时,尽可能的降低大企业数据平台的运维成本。使企业的大数据平台成为高可扩展性、高灵活性、高可用性、成本低廉的大数据运算平台。
大数据时代背景:
“大数据”的诞生:
半个世纪以来,随着计算机技术全面融入社会生活,信息爆炸已经积累到了一个开始引发变革的程度。它不仅使世界充斥着比以往更多的信息,而且其增长速度也在加快。信息爆炸的学科如天文学和基因学,创造出了“大数据”这个概念*。如今,这个概念几乎应用到了所有人类智力与发展的领域中。

21 世纪是数据信息大发展的时代,移动互联、社交网络、电子商务等极大拓展了互联网的边界和应用范围,各种数据正在迅速膨胀并变大。
互联网(社交、搜索、电商)、移动互联网(微博)、物联网(传感器,智慧地球)、车联网、GPS、医学影像、安全监控、金融(银行、股市、保险)、电信(通话、短信)都在疯狂产生着数据。
地球上至今总共的数据量:
在2006 年,个人用户才刚刚迈进TB时代,全球一共新产生了约180EB的数据;
在2011 年,这个数字达到了1.8ZB。
而有市场研究机构预测:
到2020 年,整个世界的数据总量将会增长44 倍,达到35.2ZB(1ZB=10 亿TB)!
环亚时代-CFB平台定位:
一键快速部署:
100-1000台节点,可在30分钟内部署完成。
可视化运维监控:
不仅仅可监控节点的物理资源,同时可监控节点上任务执行情况
多租户任务调度:
用户间执行作业任务相互隔离,从而实现基础架构共享
全系统高可用性:
不仅仅是Hadoop Name Node的HA,更有计算、存储、服务、网络全方位HA设计
环亚时代-CFB平台功能架构:
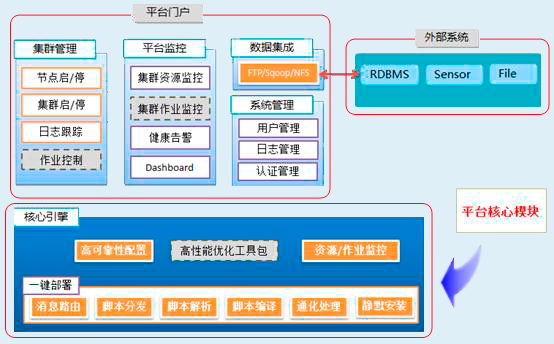
环亚时代-CFB平台为企业带来的收益:
快速搭建大数据平台
CFB平台能辅助企业IT部门,以更短时间搭建适合本企业的大数据平台。可在30分钟内实现100至1000个节点集群环境搭建。
可视化运维监控
CFB平台通过可视化管理控制台,监控集群环境物理资源参数,同时可监控集群环境每个节点作业执行状况参数。
丰富的数据集成手段
CFB平台数据集成接口由开源大数据集成工具、自助研发的数据同步接口等手段组成,可实现对RDBMS、FILE、Sensors等多格式数据源集成。
存在的问题
现代企业随着海量数据TB级和PB级的不断增长,上千并发访问用户数的增多,以及对系统响应时间缩短的要求,传统的计算机信息系统还是满足不了关键业务的大并发和低延迟的要求。
现代计算机系统的处理器的综合处理能力远远大于其它计算机组件,而磁盘的读写速度和延迟尽管也得到了提高和缩短,但和CPU处理能力比起来还相差甚远。尽管内存速度的提高和固态磁盘的采用不同程度地提高了数据处理的速度,但在处理大并发用户和低延迟响应时,仍然满足不了大型企业和对响应时间要求很高的企业的要求,这主要归结于对数据的读写速度最终有赖于底层磁盘的读写速度慢的原因。
因此如何提高应用性能,缩短服务响应时间、增加并发用户数同时具有高可用性、高可靠性、高扩展性以及数据持久性,满足云计算和大数据环境下多租户的性能需要,成为关键性业务迫切需要解决和云计算面临的问题。
内存计算技术
针对以上企业用户的问题和挑战而出现的内存计算技术不同于传统的数据存储和处理技术,传统的数据存储和处理技术把主要大量数据存储在距离CPU最远的磁盘上,内存仅作为提高重复读写的命中率数据缓存使用,而内存计算技术把全部数据或常用的数据存放在主存中,大大提高了数据处理的速度和缩短了业务的响应时间,比传统数据存储和处理快几十倍或更多,解决了关键业务用户的性能问题。
随着计算机硬件处理速度的提高、内存价格的降低、内存计算技术的成熟,以及高端企业用户对性能的需求使得内存计算技术近几年来得到了大量使用,而且不同程度地把内存计算技术嵌入传统的应用软件中,大大提高数据存储和处理的速度。
内存计算技术主要分为三类,即内存数据管理技术(包括内存数据网格技术、内存数据库技术)、内存应用平台技术和高性能消息架构技术。其中内存数据网格技术更为成熟并得到了使用,内存数据库技术也逐渐得到了应用。
内存数据网格由多个内存计算节点组成,每个节点配置一定数量的内存,通过管理节点构成分布式的内存数据网格,保持内存数据和计算节点本地化,减少节点间的数据传输量,从而提高数据计算速度,可以用更少的响应时间为用户提供服务,利用内存数据的多个复本实现高可靠的数据存储,在节点失效时不影响计算的进行和性能,同时利用内存数据分区技术实现数据存储性能的线性扩展,在系统运行时可以通过增加内存节点或删除内存节点实现系统的可伸缩性。
通过构建内存数据网格,可以实现高性能的、分布式的、高可靠的、可伸缩的和一致的内存数据计算,使得多个分布式应用如事务处理和分析操作在低延迟的共享分布内存中进行,同时利用内存分布式复制和分区技术实现内存数据的一致性、可用性和持久性。
基于GemFire的内存计算方案
一、针对应用服务器的HTTP会话管理的解决方案
传统的中间件服务器如Tomcat等在构建群集系统时,需要配置群集之间的内存HTTP会话复制,以提高性能和高可用性,但在处理大量会话时往往满足不了用户的高扩展性要求,而vFabric GemFire 可以卸载应用服务器的大量HTTP 会话并管理其状态,提供经验证的高可用性和可扩展性,解决了需要横向扩展以满足需求的 Web 应用的难题。
二、针对Hibernate L2 Cache管理的解决方案
Hibernate L2 Cache介于应用程序的数据访问层和Oracle、SQL server、DB2数据库之间,为Hibernate提供持久化的二级缓存,而GemFire 可以为 Hibernate 提供快速、可扩展和分布式的二级缓存,可以改善Hibernate的性能并大幅减少访问数据库的网络流量,大大缩短应用的响应时间。Gemfire Hibernate L2 Cache模块可以利用Gemfire内存数据的众多特性,具有很强的可伸缩性,如数据在群集中分区、支持分层缓存、支持所有的Hibernate并发策略,同时保证数据一致性。
三、针对数据库的内存数据网格解决方案
SQLFire是在GemFire数据网格技术的基础上,融入了Derby分布式数据库和扩展的标准SQL而形成的专用的内存数据库解决方案,除了具有GemFire的所有特性外,还具有配置部署简单、提供复杂的SQL查询引擎和基于成本的优化器,而且降低内存数据库的学习曲线,特别适合具有关系型数据库和标准SQL使用经验的企业和人员使用。
基于GemFire的内存计算案例
我们已经同VMware公司紧密配合,完成了某银行内存数据网格的前期测试、设计和规划,在GemFire的初步测试中,使得数据库的并发读写性能得到了10倍以上的性能提升,大大缩短了系统的响应时间,为客户提供了满意的解决方案,解决了用户业务面临的性能和可扩展性问题,并将会在初期部署使用成功的基础上得到大面积的部署,向企业级内存数据网格迈进。
我们将根据用户需求为用户提供如下基于GemFire内存计算技术的服务:
调研用户的应用环境和性能需求并提出初步的性能改进设计方案 模拟用户计算场景的GemFire内存计算POC验证测试 GemFire内存计算方案的部署、实施和运维 基于GemFire结合用户数据库,使用GemFire API部署内存数据库 基于SQLFire结合用户数据库应用提供高性能的内存数据库的设计和部署